
When a Test Fails: Solving Automated Triage
You’re running down the hallway of your alma mater in your bathrobe. You’re late for your final, and you don’t remember where the classroom is. How is that even possible! The bell rings.
It’s not a bell. It’s PagerDuty, and it’s 2 AM. It was all just a dream! But the alarm isn’t.
Unfortunately, it’s still a nightmare: the alarm is going off in a part of the system you didn’t work on, and you’re pretty sure it was vibe-coded recently (and probably vibe-reviewed). Is it a bug, or just an environment hiccup?
At Ranger, we have to diagnose test failures thousands of times a day, at all hours. Triage is core to our service - when a test fails, we need to tell our customers as quickly as possible whether it’s an indication of a real problem. If it’s not, our test-healing FixTest agent needs to know exactly what went wrong to get the test back online. Early versions of this system were not successful and required a lot of babysitting - but over the past month we’ve invested serious time and tokens in improving the agent’s accuracy and depth. The result has been a 400% improvement.
In this article, I’m going to tell you how we did it, and how it relates to building agents of all types.
Solving real-world problems with LLMs is still difficult, even when the domain is well-understood, even when there is a “correct answer.” This compounds when the answer is a matter of tradeoffs, or when the answer isn’t directly in the context they ingest via the prompt or tool calls.
Not all test failures are caused by bugs. Not all bugs are important enough to get prioritized. Alarm fatigue and changing products mean that teams sometimes start to ignore test failures. Thus the goal of the Triage agent is to be high-signal: we want to report fewer bugs, and they should be issues that are important enough to resolve. We have to think very carefully before picking up the red telephone.
In the end, we learned 3 critical things:
- You need to have an excellent way of evaluating the agent to iterate quickly
- You need to understand the problem and ask the right questions
- You need to understand how agents think, how to break down the problem, and how to structure context
Evaluating an Agent
The first version of our Triage agent followed a similar approach to end-to-end testing. When diagnosing why a test failed, we instructed the agent to log into the app, interact with it the way a user would, and try to reproduce the issue. But this first version wasn’t very effective: More than 50% of the bugs the agent created were being canceled. On the question of bug/not-bug, we were doing worse than random chance.
Since then we’ve tried more than a dozen versions of the Triage agent, trying both simple and complex prompts of all kinds.
In the early days, we implemented changes strictly based on vibes. If you couldn’t immediately tell that it was better, it wasn’t better enough. That worked OK when we were first starting out, but we quickly realized we needed to be more scientific.
If you want to improve something, you need to be able to define success, and ideally have some way to measure it. We needed a way to consistently and conveniently determine whether each change to the agent was making it better or worse.
Just building the eval itself required two major pieces: a repeatable way to score correctness, and an automated solution to run the scoring test consistently with each change. Without the automated system, we never would have been able to iterate as quickly as we did, and the time cost would have eventually sunk the project or forced us to accept mediocre quality.
The first part of the challenge was defining success though, and we had to identify where the agent was coming up short - with numbers, not vibes. This turned out to be harder than you might expect for a problem with a “correct answer.”
The original question
When we started this work, the Triage agent made a binary decision per test failure:
- bug_created: this is a real product bug
- under_maintenance: this is a test or infrastructure issue - send it to our FixTest agent.
If a failure is not due to a bug, FixTest should update the test to align to new features and product expectations.
Simple enough.
The convenient thing about this question is that ground truth labels itself over time - a bug that gets resolved by the customer was a correct call; a bug that gets canceled was a false positive. We just had to look at historical outcomes:
| Actually a bug | Not a bug | |
|---|---|---|
| Agent said: bug | Customer resolved the bug - Correct | Customer canceled the bug - False positive |
| Agent said: not a bug | A real bug was filed later - Missed bug | No bug emerged later - Correct |
Our first analysis told us what we already knew: Triage had room for improvement.
But this didn’t tell us why, and you can’t fix what you don’t understand. We had to dig into the details and identify patterns in the successes and failures.
Finding the patterns
Our first analytical pass was fast, and less expensive than deep LLM analysis on every historical agent execution. When our Triage agent creates a bug or dismisses a failure, it writes a rationale. We scanned every rationale from every failure case against a set of keyword categories:
| Category | Keywords |
|---|---|
| Environment | environment, infrastructure, seed data, database, server, backend, deploy |
| Flaky | flaky, intermittent, retry, sometimes, sporadic |
| Timeout | timeout, timed out, slow, loading, wait, took too long |
| Uncertainty | cannot determine, uncertain, unclear, unsure, ambiguous |
| … | 14 categories total |
From this initial grouping, we sampled each category and fed a subset of them into an agentic full-details review and critique. We asked an LLM to read the entire Triage reasoning chain from each execution alongside the eventual human-confirmed outcome.
Each case got a structured prompt with the agent’s reasoning, human-labeled bug details, and the time gap between the two. We did this on thousands of cases.
Surprising Results
It turned out that a lot of what we’d been labeling as “false positives” weren’t. Many of them were real issues - they just weren’t important to the customer. Some were caused by a misconfigured test account. Others were caused by instability in a customer’s testing environment.
Issues were being cancelled, and our scoring logic was counting every cancellation as an agent failure.
But the agent wasn’t wrong that something was broken. It was wrong about what kind of broken - and it didn’t have the vocabulary to express the difference.
The question itself was the problem, and forcing the agent to choose between two wrong options. Consider a test that fails because it gets a 403 when trying to perform an action. That could be:
-
A bug in the customer’s permissions system
-
A configuration issue where the test user wasn’t granted the right role
-
A transient environment outage
The agent had two choices: create a bug, or send it to FixTest. But FixTest only has access to test code and test run traces - it can’t fix a customer’s environment outage or a misconfigured test user. There was no “correct answer” for a meaningful share of the cases we were evaluating - and the poorly defined categories were confusing both the AI and our users.
In these cases, the agent wasn’t wrong - we were asking it the wrong question.
Which question first?
Triage is a classification problem, with decisions being made from rich context. Each decision branches into different behaviors in our system, and the branches are ordered by the needs of our implementation. If you get the first question wrong, every downstream agent pays for it.
The two main paths an agent can take after triage are still essentially the same: Try to fix it, or tell someone. The question here is: “Can we fix this by modifying test code?”
Let’s say you’ve implemented a new step in your onboarding wizard, and the tests covering the wizard fail because there is new data to enter or new choices to make. That’s not a bug, it’s a changed product expectation - we can fix this by updating the test.
On the other hand, if your submit-handling endpoint is throwing HTTP 500 errors, that problem is on your end. In that case, the failure’s next stage of life is a draft bug. We’ll need to gather more context to determine whether it’s a bug, something transient, or something related to test setup.
This change eliminated the impossible middle ground. The agent no longer needs to distinguish between a product regression, a permissions misconfiguration, and an environment outage at the first stage. It just needs to determine whether the failure is something our test-repair agent can address.
Building the golden eval set
With the reframed question - “can FixTest fix this?” - we curated a set of golden cases from our forensic data. These are genuine test failures that occurred in the past with known correct outcomes. We stratified these events across two axes: difficulty and expected decision.
The expected decisions now mapped cleanly:
-
Yes, FixTest can fix it: the test code needs updating - a product change, a selector issue, a timing problem
-
No, FixTest can’t fix it: there’s something going on in the customer’s app, environment, or configuration - file a draft bug
Within each category, we deliberately included a spectrum of difficulty. This was critical. Early iterations of the eval showed near-perfect scores on easy cases while missing the hard ones entirely.
We had previously been penalizing the agent heavily for reporting a genuine application issue if it turned out to be an environment issue, or even if it was a bug, but the customer never prioritized fixing it. According to the new taxonomy, these classifications were actually correct.
The replay environment
When iterating on an agent, you need to be able to run experimental jobs without affecting your production environment. In our case, the eval needed to repeatedly recreate production test failures - with all their original context, against a real database with real data - without polluting prod databases or sending messages to actual customers.
We already had the infrastructure for this: Ranger’s preview environments, which spin up isolated GCP VMs with Neon database branches derived from a sampled and anonymized version of non-sensitive production data. The same system that lets our background agents safely develop and test features now lets us safely replay agent executions against prod-equivalent data in a sandboxed environment.
Building on top of that, the eval pipeline itself is a set of scripts driven by GitHub Actions. When a PR is labeled with TriageEval, the workflow:
-
Provisions a preview environment with a fresh Neon branch
-
Loads a “golden” test failure dataset - a JSON file of 100 curated failures and their expected outcomes
-
Replays each golden event against the PR’s code via the preview API
-
Polls for completion, then exports results as NDJSON to cloud storage
-
Scores the results against the golden set
Scoring and gating
The scoring script matches each replayed event back to its golden case and compares the agent’s decision against the expected outcome.
Our research and experiments led us to a refined taxonomy based on the actual cases we were seeing in production. Figuring out whether we could fix the test automatically turned out to be the first question, but that’s only the first link in a chain. We also must determine whether a customer-side issue is actually a bug, and how important it is. For that, we use the next layer of the Triage pipeline - BugVerifier - whose job is to take those draft bugs and further disambiguate:
-
Real application bug - a genuine regression or defect in the customer’s product
-
Customer environment issue - their staging is down, their API is rate-limited, their CDN is misbehaving
-
Data setup issue - the test user doesn’t have the right permissions, required seed data is missing
This is how the first stage of Triage (FixTest vs Draft Bug) is now evaluated:
| Category | Subcategory | What it tests |
|---|---|---|
| Draft Bug | Genuine bug | Actual product regressions - broken features, error states |
| Intermittent bug | Real bugs that manifest inconsistently - race conditions, flaky APIs | |
| Data setup bug | Test user misconfiguration, missing permissions, bad seed data | |
| FixTest | Product change | UI legitimately evolved - button moved, copy changed, new modal |
| Test construction | Poorly written test - bad selectors, insufficient waits, brittle assertions |
When a PR merges to main, its scorecard becomes the new baseline. Future PRs are compared against it. Number go up!
Agent Psychology
Working memory and cognitive load are well-established concepts in psychology: People tend to hyperfocus on certain instructions. There is a limit to how many instructions we can follow.
If you’ve been building agents lately, you’ve probably noticed that LLMs have similar limitations. For example, the difference between the words “might” and “probably” when used in a prompt can be astonishing: “might be a regression” and “probably a regression” yielded totally different outcomes in Triage. When given the full history of a test, we found that agents were far more likely to flag something as an environment issue if there had been flakes in the past, even when there were glaring bug signals like error messages and 500s in the network log.
Agents are better at following short, clear instructions and fail spectacularly when given conflicting instructions, unbalanced information, or when forced to choose between two bad options.
Several early versions of Triage were allowed to choose between many or all of the possible classifications of a test failure in a single pass. This led to poor results; the agent had a tendency to always choose whatever it saw as a “safe” option when one was available; failures were constantly misclassified as bugs, apparently to be “on the safe side”, or as flakes more or less whenever the agent didn’t have a concrete answer.
The most reliable solution has been a slightly complex orchestration of relatively simple prompts. Each prompt is responsible for a dedicated task: narrowing down a single type of information into high-signal context for the final decision-maker to consume:
Decomposing Triage into a chain of focused classification steps made each step manageable - instead of one agent trying to answer a three-or-four-way question through a binary interface, each link in the chain gets its own context, its own prompt, and eval coverage.
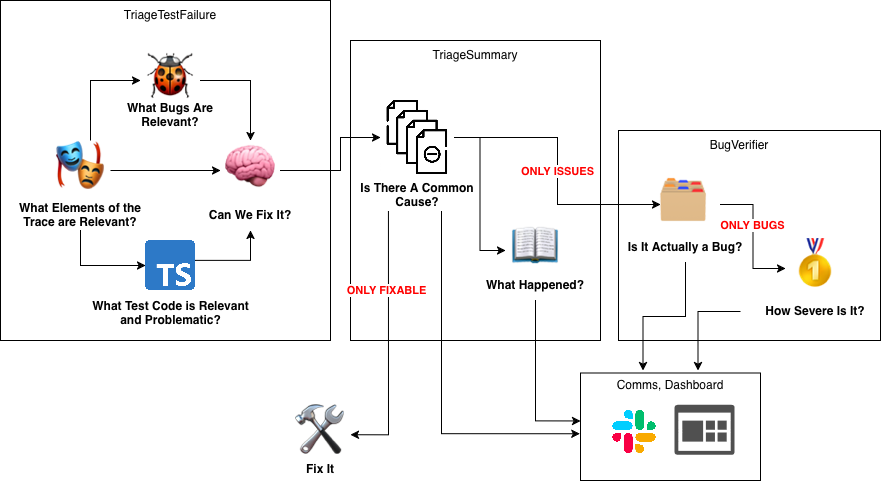
Even this taxonomy has edges. Say a test fails after waiting 60 seconds for an API response - is that a test that should be more patient, or is that a broken UX that should be flagged? We’ve had customers argue both sides. But at least now this ambiguity can be addressed with appropriate context, rather than hidden in a binary choice that punishes the agent no matter what it picks.
In March 2026, building reliable agents is still difficult. It takes thought, patience, balance, and a high willingness to trade tokens for confidence. You need to be excellent at analyzing the data, understanding the problem, and asking the right question.
What’s Next?
We’re still learning and improving. No doubt someday we will revisit Triage and learn new things again. For now, we’ve shifted this intensity of focus to our test-fixing and test-writing agents. We’re taking the high-quality output of the Triage agent and building it into FixTest, and making all of our code-writing agents interactive so they can be supervised and guided in real-time by our team and our customers. No doubt we will learn surprising things there as well, and be pushed to challenge our assumptions once more.